MongoDB 生产环境下副本集部署和调优
一、副本集说明
如果你了解mysql的主从架构和读写分离技术,那么副本集也就是使用了类似的技术
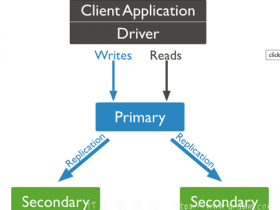
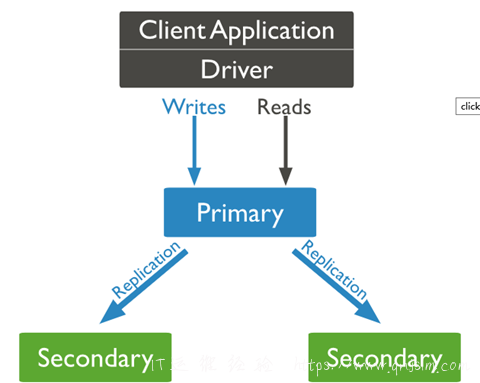
主服务器primary 会接受客户端的读写,通过Oplog 把数据同步到从服务器上Secondary,当然副本集中从服务器是天生提供读操作的。
以下是架构原理
二、为什么不选择主从模式
主从模式现在基本已经放弃使用了,确定是主服务器挂掉,从服务器不会自动顶替,需要手工切换,相当于是一个冷备节点,副本集可以理解成高级的主从模式,完善了缺点,可以实现主节点挂掉,从服务器会顶替。
三、节点数量说明,仲裁节点
安装副本集,我们需要基数个节点(例如3,5,7,9……..),如果你选择一个节点我也无话可说了,为什么是基数个节点了,这是副本集在群集选举的时候需要,具体过程大家可以参考官方文档或者mongo群集切换日志了解,我看国内所有网站上都说我们安装时需要两个数据节点和一个仲裁节点,其实这是不对的,先来说说仲裁节点的作用,仲裁节点不保存任何数据,不能成为Master,那它是做什么的了,他是参与群集切换时投票的节点。
那么问题来了,为什么有仲裁节点了?
大家习惯的数据节点都是两台,一台主,一台从,而上面说了mongo副本集需要基数个节点,那怎么办,我们再去构筑一台DB服务器,no,no,这时候我们的仲裁节点出现了,这时候官方的建议就是你可以把仲裁节点部署在我们的WEB或者其他服务器上,因为仲裁节点不保存数据,对资源消耗(CPU\MEM\DISK\NET)可以忽略不计,这样又能完成群集搭建,又能节省一台DB服务器,不是一举两得的事,
常见的部署架构
1、两个数据节点+ 一个仲裁节点(如果你的仲裁节点在单独的服务器上,乘领导没发现赶紧想办法弥补)
2、三个数据节点(一个主、两个从,该方法是比较推荐的)
注意:
1、在3.X版本中最多支持50个节点
2、注意在参选投票的时候最多只有7个节点
4、在4个以上数据节点副本集中,还是推荐去部署一个仲裁节点,不是必须的
5、还有一种节点叫做隐藏节点,不参与投票,不能成为Master,这个作用是我们备份或者跑报表使用
6、仲裁节点不要和数据节点部署在同一台服务器上,如果是虚拟机化环境,尽量让节点在不同主机上
更多类容参考官方文档
https://docs.mongodb.com/manual/tutorial/deploy-replica-set/
四、安装部署
这里我们采用三个数据节点的方式部署
Master 192.168.31.170
Slave 192.168.31.171
Slave 192.168.31.172
第一步进行数据盘格式化,在3版本中默认使用的是WiredTiger引擎,所以建议存放mongo数据的磁盘格式化为XFS格式,这个就不做演示
第二步配置系统的基本参数,如静态IP,对于这种群集得需要时间同步
部署数据节点,三台方法一样:
#准备数据库运行的用户,不推荐使用root
[root@master opt]# useradd mongo
#下载软件
[root@master opt]# wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-3.6.3.tgz
[root@master opt]# tar -xzf mongodb-linux-x86_64-rhel70-3.6.3.tgz
#mongo是二进制文件,解压直接使用,无需要编译
[root@master opt]# mv mongodb-linux-x86_64-rhel70-3.6.3 /home/mongo/mongodb
#数据目录,在生产中这里应该是一块单独的分区,分区格式是XFS
[root@ansble01 opt]# mkdir /data/mongodb/data/ -p
#新建配置文件路径
[root@master mongodb]# mkdir /home/mongo/mongodb/etc -p
#日志保存路径,这些路径都是更具自己公司实际需求来指定
[root@master mongodb]# mkdir /data/mongodb/logs/ -p
#设置目录权限
[root@master mongodb]# chown mongo:mongo /data/mongodb/ -R
写一份mongo的配置文件
[root@master mongodb]# vim /home/mongo/mongodb/etc/mongod.conf
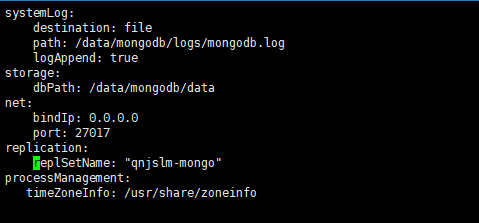
#日志保存方式已经路径,注意配置文件是yaml格式和python一样空格很敏感
systemLog:
destination: file
path: /data/mongodb/logs/mongodb.log
logAppend: true
#数据存放路径
storage:
dbPath: /data/mongodb/data
#监听本地的网络
net:
bindIp: 0.0.0.0
port: 27017
#最主要的副本集设置,需要指定一个副本集名称,所有节点的副本集名称必须是一样,相当于群集名称
replication:
replSetName: "qnjslm-mongo"
processManagement:
timeZoneInfo: /usr/share/zoneinfo
配置截图
把mongo做成ssytemd系统服务器进行管控,如需要具体了解请参考systemd
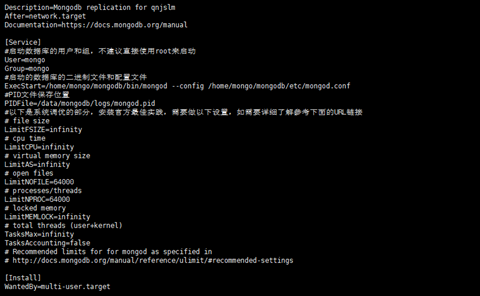
[root@master etc]# vim /lib/systemd/system/mongod.service
[Unit]
Description=Mongodb replication for qnjslm
After=network.target
Documentation=https://docs.mongodb.org/manual
[Service]
#启动数据库的用户和组,不建议直接使用root来启动
User=mongo
Group=mongo
#启动的数据库的二进制文件和配置文件
ExecStart=/home/mongo/mongodb/bin/mongod --config /home/mongo/mongodb/etc/mongod.conf
#PID文件保存位置
PIDFile=/data/mongodb/logs/mongod.pid
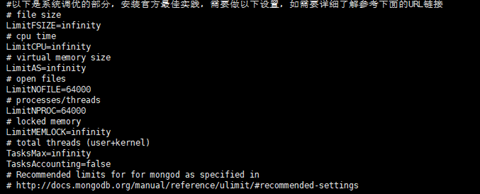
#以下是系统调优的部分,安装官方最佳实践,需要做以下设置,如需要详细了解参考下面的URL链接
# file size
LimitFSIZE=infinity
# cpu time
LimitCPU=infinity
# virtual memory size
LimitAS=infinity
# open files
LimitNOFILE=64000
# processes/threads
LimitNPROC=64000
# locked memory
LimitMEMLOCK=infinity
# total threads (user+kernel)
TasksMax=infinity
TasksAccounting=false
# Recommended limits for for mongod as specified in
# http://docs.mongodb.org/manual/reference/ulimit/#recommended-settings
[Install]
WantedBy=multi-user.target
配置截图
启动和设置开机启动
[root@master etc]# systemctl enable mongod.service
[root@master etc]# systemctl start mongod.service
把mongo二进制文件放入到PATH变量中,这步不是必须的,只是我们方便命令操作
[root@master opt]# vim /etc/profile
在文件最后插入如下代码
export PATH=$PATH:/home/mongo/mongodb/bin
保存退出执行source 让配置立即生效
[root@master opt]# source /etc/profile
☆其他两节点按照上面的步骤配置完
1、保证三个节点mongo服务都正常运行
2、如果服务器上运行了selinux,需要设置27017端口,还需更具公司策略需求修改默认端口为其他
3、防火墙设置,三台节点间端口得互通,还有前端服务器,根据需求调整
4、如果公司有要求,还需要配置数据库认证
初始化mongo副本集
在其中任意一台服务器上使用mongo工具链接上任意一台DB服务器
[root@master opt]# mongo 127.0.0.1
输入如下命令初始化群集
rs.initiate( {
_id : "qnjslm-mongo",
members: [
{ _id: 0, host: "192.168.31.170:27017" },
{ _id: 1, host: "192.168.31.171:27017" },
{ _id: 2, host: "192.168.31.172:27017" }
]
})
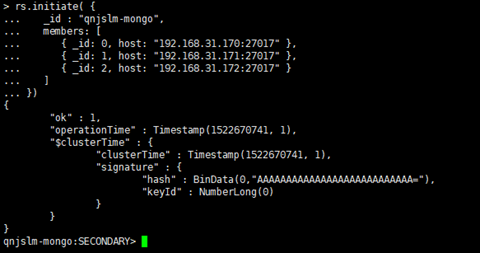
_id : "qnjslm-mongo",
这个就是我们的集合名称,得和配置文件中定义的一至
{ _id: 0, host: "192.168.31.170:27017" },
这就是添加节点,ID从0开始,后面是IP和端口
另外如果需要后期添加节点,使用rs.add("192.168.31.173:27017") 这样即可删除就是remove
使用rs.status()可以查看一下群集状态,
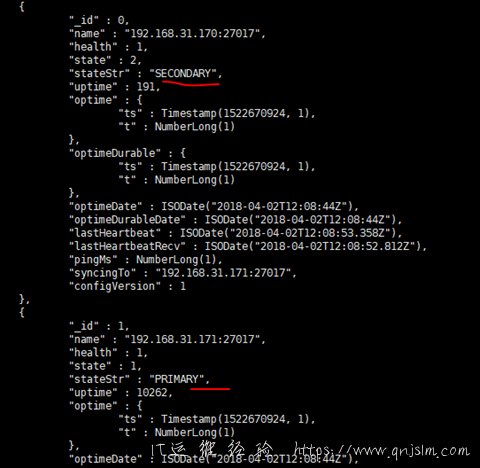
一般是你在那个节点上操作,这个节点默认会成为主节点,既然我们是群集副本集状态,那么当然是可以切换的,有两种办法,比较野蛮的是把服务重启,这个是不建议做的,另外就是链接数据库使用 rs.stepDown()进行操作

安装就到这里,下面说说一些调优
五、相关性能调优
官方给出的性能调优有如下几条,进行逐条说明
-
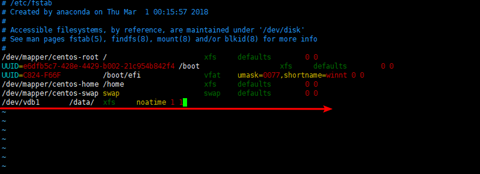
Turn off atime for the storage volume containing the database files.
在挂在数据盘的时候加入noatimek选项,如图
/dev/vdb1 /data/ xfs noatime 1 1
-
Set the file descriptor limit, -n, and the user process limit (ulimit), -u, above 20,000, according to the suggestions in the ulimit reference. A low ulimit will affect MongoDB when under heavy use and can produce errors and lead to failed connections to MongoDB processes and loss of service.
该优化我们在做systemd服务的时候已经把相关优化参数设置,如下图部分
下面我们来看看如何验证是否修改成功
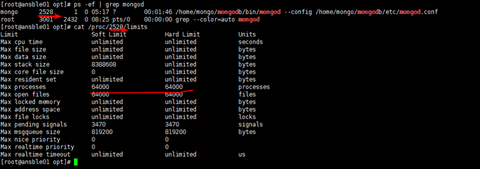
首先我们通过ps找到mongo运行的进程PID,这里是2528
然后查看进行运行文件,确认限制是否生效,大家应该知道系统默认最大的文件打开是1024.
[root@master opt]# ps -ef | grep mongod
[root@master opt]# cat /proc/2528/limits
-
Disable Transparent Huge Pages. MongoDB performs better with normal (4096 bytes) virtual memory pages. See Transparent Huge Pages Settngs.
禁用透明大页TPH,这个优点繁琐,一步一步操作就好,如果没有配置好在链接mongo就会有相关提示

第一步、 创建启动文件,每次开机进行执行关闭
[root@master mongodb]# vim /etc/init.d/disable-transparent-hugepages
#!/bin/bash
case $1 in
start)
if [ -d /sys/kernel/mm/transparent_hugepage ]; then
thp_path=/sys/kernel/mm/transparent_hugepage
elif [ -d /sys/kernel/mm/redhat_transparent_hugepage ]; then
thp_path=/sys/kernel/mm/redhat_transparent_hugepage
else
return 0
fi
echo 'never' > ${thp_path}/enabled
echo 'never' > ${thp_path}/defrag
re='^[0-1]+$'
if [[ $(cat ${thp_path}/khugepaged/defrag) =~ $re ]]
then
# RHEL 7
echo 0 > ${thp_path}/khugepaged/defrag
else
# RHEL 6
echo 'no' > ${thp_path}/khugepaged/defrag
fi
unset re
unset thp_path
;;
esac
设置执行权限以及开机启动
[root@master mongodb]# chmod 777 /etc/init.d/disable-transparent-hugepages
[root@master mongodb]# chkconfig --add disable-transparent-hugepages
确认开机状态状态
[root@arbiter mongodb]# chkconfig --list

我们手动执行脚本,让马上生效
[root@master mongodb]# /etc/init.d/disable-transparent-hugepages start
对于redhat和centos,还需要修改tuned和ktune
[root@master mongodb]# mkdir /etc/tuned/no-thp
[root@master mongodb]# vim /etc/tuned/no-thp/tuned.conf
[main]
include=virtual-guest
[vm]
transparent_hugepages=never
让其立即生效
[root@master mongodb]# tuned-adm profile no-thp
验证
[root@master mongodb]# cat /sys/kernel/mm/transparent_hugepage/enabled
[root@master mongodb]# cat /sys/kernel/mm/transparent_hugepage/defrag
以上两条命令输出内容都应该是下面内容,中括号在never上
always madvise [never]
-
Disable NUMA in your BIOS. If that is not possible, see MongoDB on NUMA Hardware.
确认是否是NUMA架构,输入下面的命令,如果出现NUMA,就是NUMA架构
[root@master ~]# grep -i numa /var/log/dmesg
现在一般我们是在虚拟机上进行部署,不涉及到NUMA 架构,如果真的遇到了,如果物理主机可控,就从BIOS中禁用就好,如果物理机不可控,那使用下面的方式
[root@master etc]#echo 0 | sudo tee /proc/sys/vm/zone_reclaim_mode
[root@master etc]# sysctl -w vm.zone_reclaim_mode=0
[root@master etc]# yum install -y numactl
[root@master etc]# vim /usr/lib/systemd/system/mongod.service
#修改原来的启动,使用numactl 来启动
ExecStart=/usr/bin/numactl --interleave=all /home/wanplus/mongodb/bin/mongod --config /home/wanplus/mongodb/etc/mongod.conf
-
Problems have been reported when using MongoDB with SELinux enabled. To avoid issues, disable SELinux when possible.
禁用Selinux
[root@master etc]# vim /etc/selinux/config
SELINUX=disabled
[root@master etc]# setenforce 0
如必须使用selinux时,添加下面规则,假如你的端口是默认的27017
[root@master etc]#semanage port -a -t mongod_port_t -p tcp 27017
关于优化其实还有很多的小细节,这个只能在实际使用中去调整了,例如设置交换分区,oplog大小、控制缓存大小等
mongo是一个吃内存的应用,所以控制尽量少的时候交换分区
查看现有设置
[root@slave /]#cat /proc/sys/vm/swappiness
临时修改设置
[root@slave /]#sysctl vm.swappiness=1
长期修改设置
[root@slave /]# vim /etc/sysctl.conf
vm.swappiness = 1
六、客户端链接测试
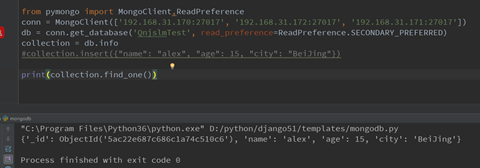
这里使用python进行测试,我们需要安装pymongo模块,代码如下,如果你运行你会发现,打印没有任何东西,这是为什么了,这里应为我们设置了read_preference参数,指定优先从SECONDARY节点获取数据,实现读写分离,当你插入数据就去获取,当然是没有的啦,稍等片刻就会有了
from pymongo import MongoClient,ReadPreference
conn = MongoClient(['192.168.31.170:27017', '192.168.31.172:27017', '192.168.31.171:27017'])
db = conn.get_database('QnjslmTest', read_preference=ReadPreference.SECONDARY_PREFERRED)
collection = db.info
collection.insert({"name": "alex", "age": 15, "city": "BeiJing"})
print(collection.find_one())
关于read_preference参数可以指定以下5种,副本集模式下哦
PRIMARY:默认选项,从primary节点读取数据
PRIMARY_PREFERRED:优先从primary节点读取,如果没有primary节点,则从集群中可用的secondary节点读取
SECONDARY:从secondary节点读取数据
SECONDARY_PREFERRED:优先从secondary节点读取,如果没有可用的secondary节点,则从primary节点读取
NEAREST:从集群中可用的节点读取数据
- 本文标签: 技术分享
- 本文链接: https://www.iamlk.cn/article/85
- 版权声明: 本文由Leonidax原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐



相关文章
关于
